




Ref : https://arxiv.org/pdf/2401.02777.pdf
RAISE (Reasoning and Acting through Scratchpad and Examples) is a new system developed to improve how conversational AI agents, like chatbots, work. It's an upgrade from an earlier system called ReAct(https://arxiv.org/pdf/2210.03629.pdf) . RAISE is designed to make chatbots better at remembering and using information during conversations. It has two main parts: a "Scratchpad" for short-term memory, which keeps track of recent conversation details, and a long-term memory part that finds and uses older, relevant information. This setup helps the AI understand and respond better in conversations.
The process of building a chatbot with RAISE involves several steps. These steps help the chatbot learn how to handle conversations more naturally and effectively, especially in complex and changing situations.
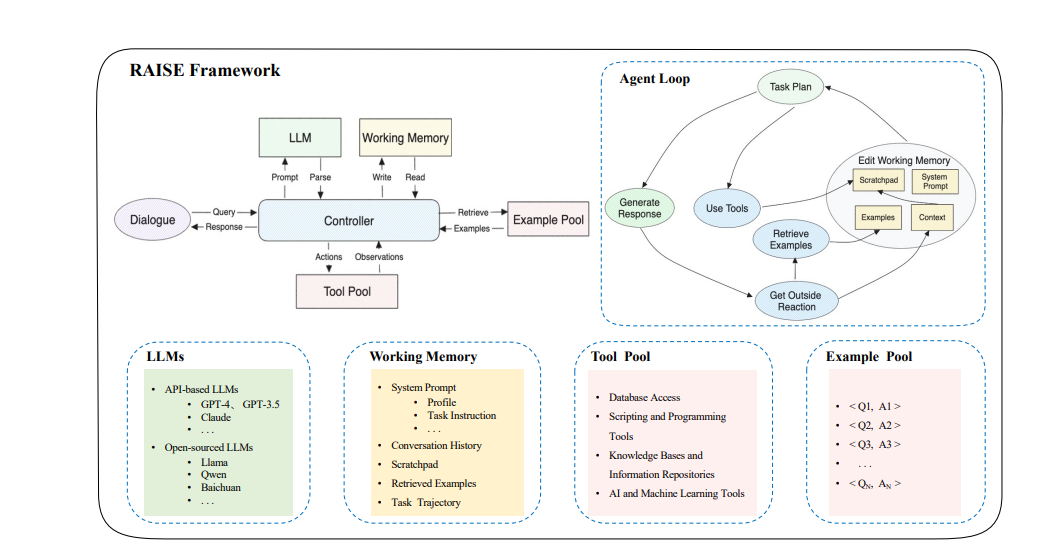
It has several main parts:
Dialogue Module: This is where the chatbot talks to users. It gets questions from users and gives back answers.
LLMs (Large Language Models): These are the 'brain' of the chatbot. They help the chatbot understand things, plan for specific tasks, use tools, and summarize information.
Memory Module: This part helps the chatbot remember things. It has four components:
System Prompt: It has basic information like the chatbot's role and instructions.
Context: This keeps track of the conversation history and what the chatbot is currently doing.
Scratchpad: This is like a notepad where the chatbot writes down important things to remember during a conversation.
Examples: These are past conversations that the chatbot uses to help answer new questions.
Tool Module: This part adds extra features to the chatbot after its basic training. It includes things like databases, APIs, and other systems to help the chatbot get more information.
Controller: This is like the manager of the system. It decides what the chatbot should do next after getting a question. It updates the memory, plans the task, selects and uses the right tools, and then decides how to answer the user.
How to create training data for the chatbot.
The goal is to make a small but very good dataset that fits the chatbot's specific roles and tasks. This data should be realistic, cover many different situations, and show clear thinking and planning in responses. The process has several steps: choosing real conversations, breaking them into smaller parts, adding details to show the chatbot's thought process, and making sure the data is diverse and high-quality.
Conversation Selection The process starts by picking real conversations that match certain criteria like completeness, enough back-and-forth dialogue, and good quality. These chosen conversations are then made anonymous for privacy.
Scene Extraction each part of the conversation is separated to create different samples. Each sample includes the history of questions and answers up to that point, the current question, and its answer. This helps to make sure the training data covers a variety of conversation types.
Chain of Thought (CoT) Process: Integrating a step-by-step reasoning process into the training data, showing the chatbot's approach to understanding and responding to queries.
While the first phase of the process, Scene Extraction, guaranteed variety by directly gathering varied data, and the second phase, Chain of Thought (CoT) Completion, introduced detailed CoT elements, there are still two major issues that require attention
Role Hallucination: This is when the AI, which has learned a lot of things, might show skills that don't match its intended job. For example, a chatbot made for sales might start talking about coding or cooking, which is not relevant. To fix this, they add special scenarios to the training that help the AI forget or not use these unrelated skills in certain situations.
Knowledge Hallucination: Sometimes, the AI might make up unrealistic or wrong information because it's using its general knowledge in the wrong way. To prevent this, they include scenarios in the training where the AI has to rely on its recent knowledge or tools, rather than just what it learned in the past.