

Making a system scalable


What is a Scalable Application?
Scalability refers to the ability of a system to give reasonable performance under growing demands . It should work well with 1 user or 1 million users by consuming optimal amounts of resources.
Let's start by designing the system with a single server
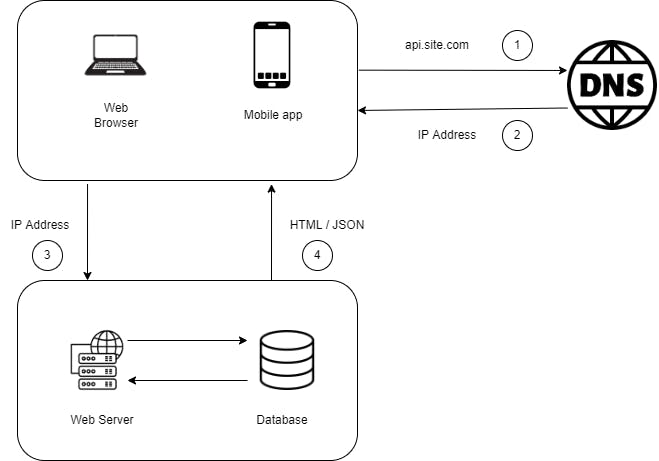
The above image illustrates a web application running on a single server : Web app ,Database , Cache etc.
Database
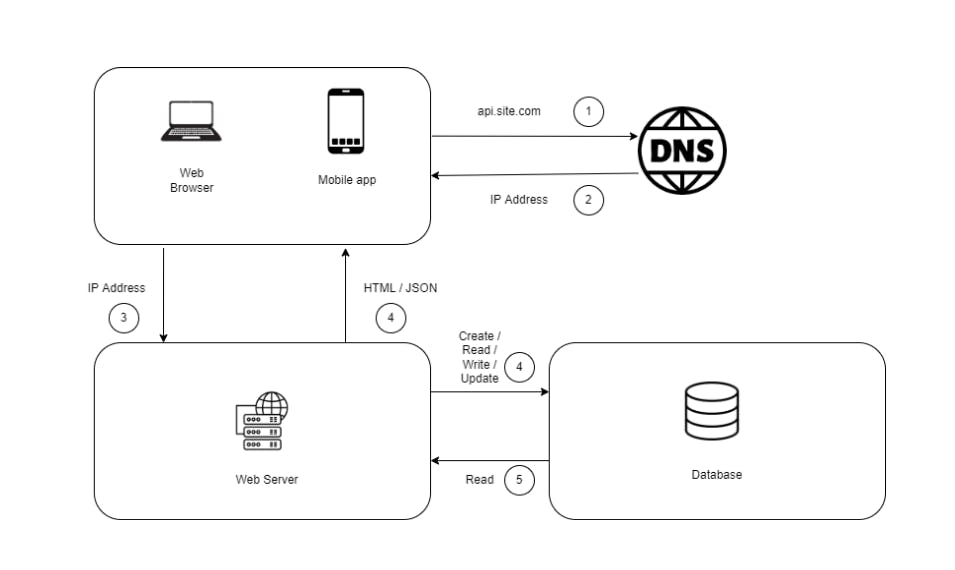
With the growing number of users the single server will become a constraint. We may need multiple servers, one for the web server and the other for the database which allows both the servers to scale independently.
Vertical scaling vs horizontal scaling
In vertical scaling (scaling up), you add more power (CPU, RAM, etc.) to your servers. In horizontal scaling(scaling out), you add more servers to your pool of resources.
When traffic is low vertical scaling is a great option considering the simplicity of the design. But we cannot add unlimited CPU /Memory to a single server. Also a single vertically scaled server may become a single point of failure.
So due to the above limitation with vertical scaling Horizontal scaling is the desirable option for large scale application.
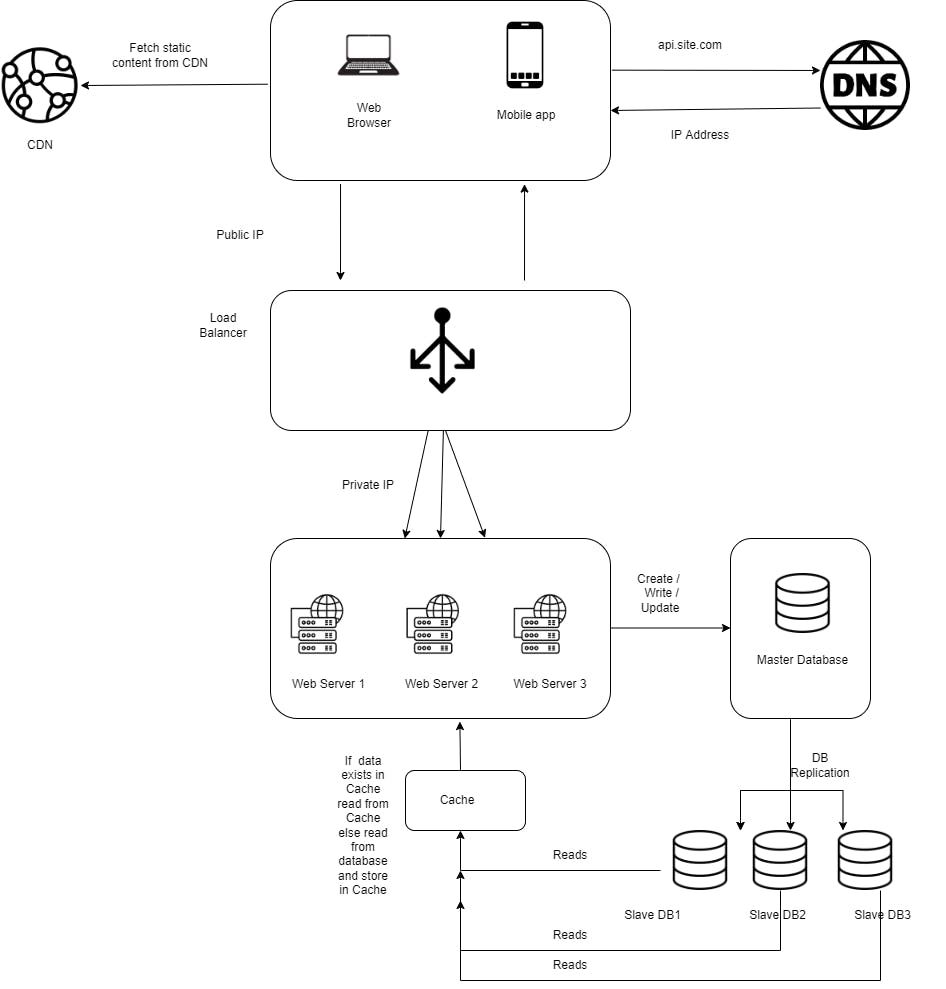
Load Balancer
Horizontal Scaling usually requires a load-balancer program which act as a front end to the collection of web servers. All incoming HTTP requests from client are resolved to the IP address of the Load balancer. The load balancer then routes each requests across servers capable of fulfilling the request in a manner that maximizes speed and capacity utilization and ensures that no one server is overworked.
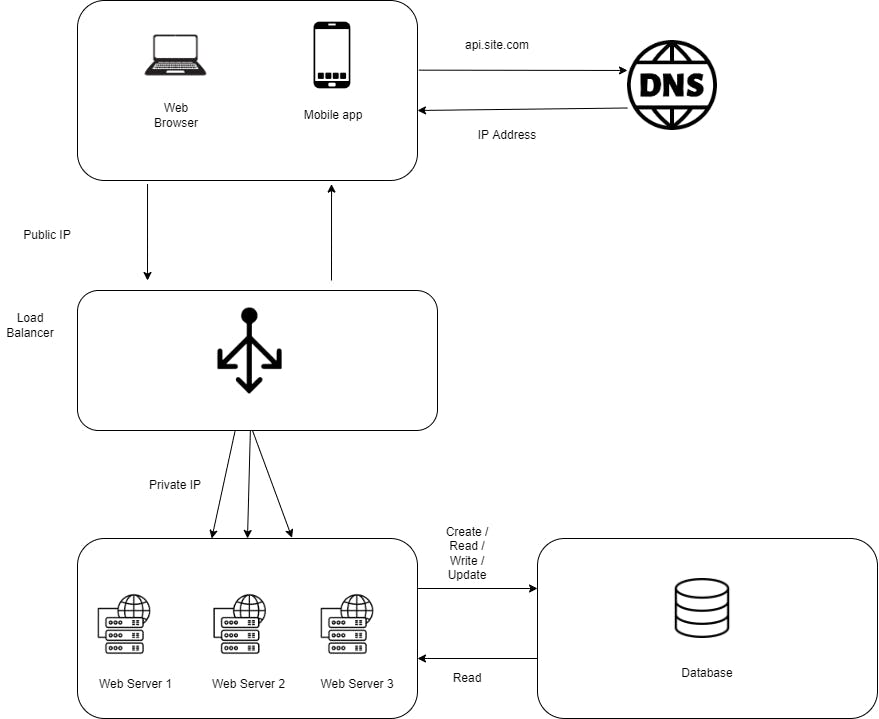
Web servers are now abstracted from the public IP address, making it easier to add or subtract servers on demand.
Currently, the web tier looks good, but there is only one database, which will become the single point of failure. Database replication is a common technique to address those problems.
Database replication
Replication means keeping a copy of the same data on multiple machines. Master-slave replication enables data from one database server (the master) to be replicated to one or more other database servers (the slaves). The master support write operations and all the slave supports read operations. Since most applications require more reads than writes, slave databases are usually larger than master databases in a system.
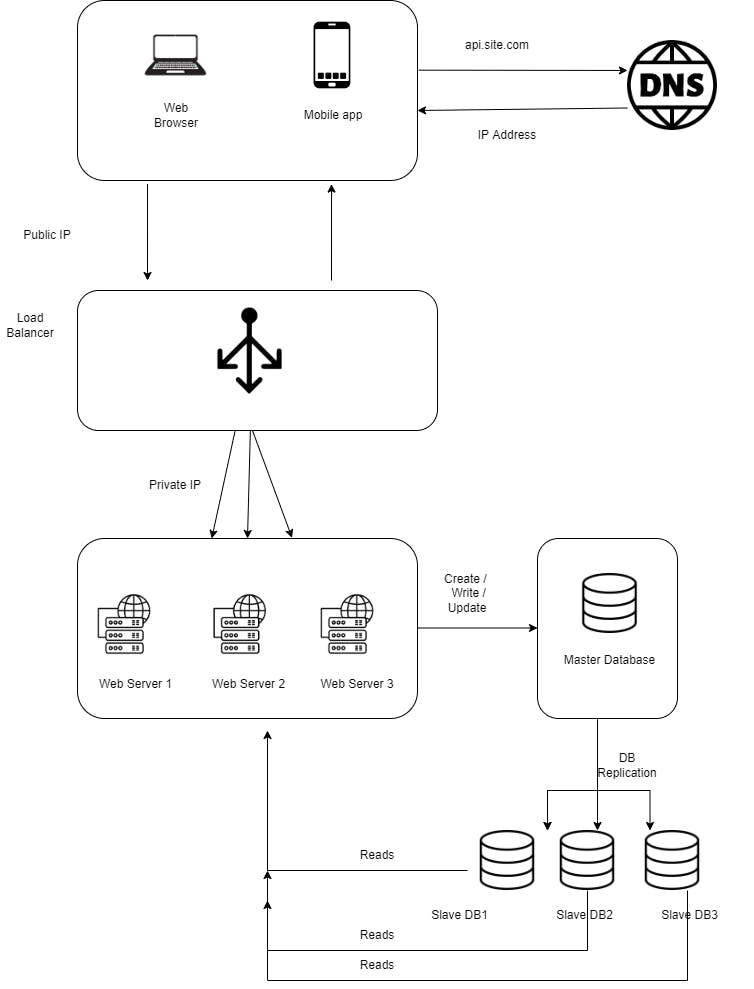
The advantages of Data Replication are
Better Performance : In Master Slave model loads are distributed across databases . It allows multiple queries to be processed in parallel which improves the performance of the system.
Reliability : We don't need to worry about data loss because data is replicated across multiple locations.
High Availability : Our application remains in operation even if a database is offline as we can access data from another slave database.
Cache and CDN
Caching can be a great way to boost performance and scalability. It is a temporary storage that stores the results of expensive responses or frequently accessed data so subsequent requests are served more quickly by minimizing database hits or network round trips. Consider using cache when data is read frequently but modified infrequently.
A content delivery network (CDN) refers to a geographically distributed group of servers which work together to provide fast delivery of Internet content. A CDN allows for the quick transfer of assets needed for loading Internet content including HTML pages, JavaScript files, stylesheets, images, and videos.
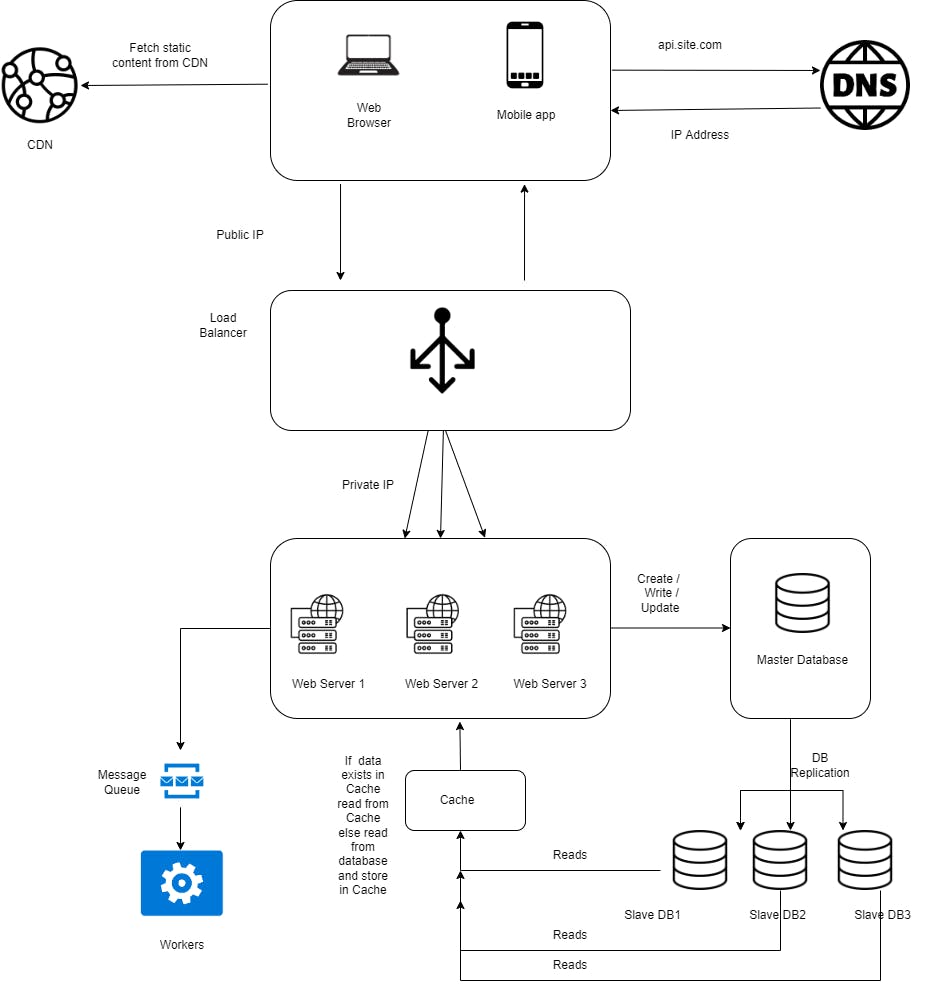
Message Queue
To further scale our system, we need to decouple different components of the system so they can be scaled independently. To solve this problem, many distributed systems use messaging queues . Your sender and receiver applications are decoupled, meaning that sender and receiver applications get to work autonomously at separate times.
Asynchronous communication also improves reliability and scalability in communication between applications and services because messages are now processed in parallel, and at separate times. In such systems, the sender does not have to wait for a response from the receiver and, therefore, can proceed with other tasks.
In addition to all the above techniques we can consider Database sharding , decoupling systems to even smaller services etc. These techniques provide a good foundation to scale beyond millions of users.