Hashtable
The use of a hash table is to make searching more efficient.
Linear search can be used to search unordered data in an array in O(n) time complexity.
Binary search can be user to search ordered data in an array in O(Log n ) time complexity.
Hashtable is a method to search data in constant time that is in O(1) time complexity . In order to improve search performance, hash tables use hashing techniques. Hash function takes the group of keys and maps it to the value.
Let us consider a simple hash function h(x) = x
In order to store [25 , 32 , 64 , 75] values using this hash function, an array of size 75 would be needed so that the three values are placed at 25 th , 32 nd , 64 th and 75 th index of the table. It might be more efficient, but it wastes a lot of space.
Lets modify the hash function to efficiently use the space in the array table.
h(x) = { x mod Size of Hashtable } (Hashtable can be of any size).
Now for example consider the Hashtable size as 10 and we want to store [25 , 32 , 64 , 75] values using the efficient hash function
25 mod 10 = 5
32 mod 10 = 2
64 mod 10 = 4
75 mod 10 = 5
What if we want to search 32 ?
Performing a similar hash function on 32 yields the same hash table index-2. We can go to the 2 nd index of an array to find the 32. This hash function is space efficient compared to the earlier hash function.But we fixed one problem and introduced a new problem.
There is a collision between 25 mod 10 and 75 mod 10 since they are both 5 and are competing for the same index.
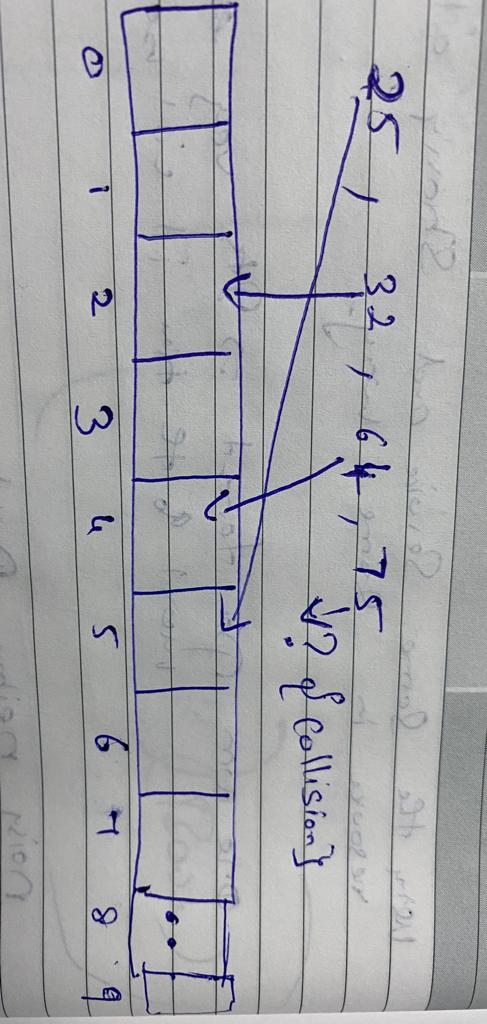
We have to resolve this collision. There are two fundamentals that can be used to tackle a hash collision:
- Separate Chaining
- Open addressing
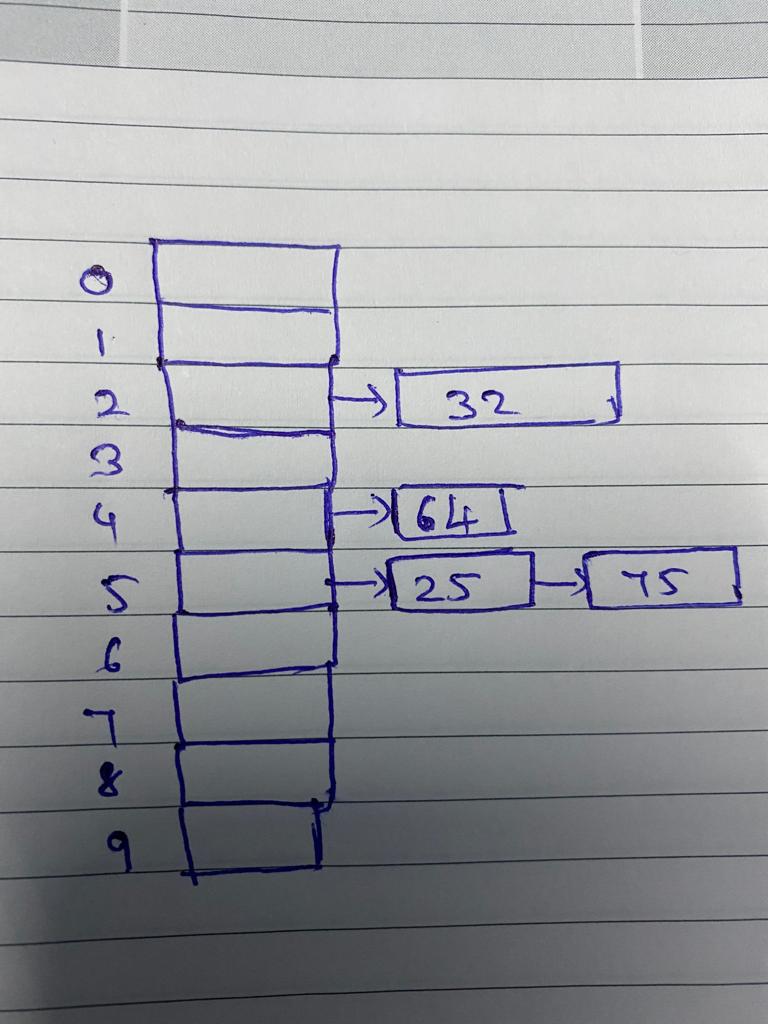
Separate Chaining
Separate chaining is one of the most common collision resolution techniques. The technique is implemented using linked lists. In separate chaining, each element of a hash table is a linked list, and it is necessary Store both elements in the same linked list if there is a collision (i.e. two different elements have the same hash value).
Open addressing
In open addressing, the key is placed at an alternative index in an attempt to resolve the collision. There are 3 types of Open Addressing:
- Linear Probing
- Quadratic probing
- Rehashing
Linear Probing
In open addressing, instead of in linked lists, all entry records are stored in the array itself. When a collision occurs In Linear Probing, the closest free slot is identified using a linear iteration over the slots. Here, the search is sequential, starting from the position where the collision occurs until no empty slot can be found.
The probing sequence for linear probing will be:
X = x mod Size of Hashtable
x= (x + 1) mod Size of Hashtable
x= (x + 2) mod Size of Hashtable
x= (x + 3) mod Size of Hashtable
....and So on until empty slot can be found
Linear probing is easy to compute but suffers from clustering many consecutive elements from groups and it starts taking time to find a free slot or to search for an element.
Quadratic probing
Quadratic probing helps us fix the clustering issue . Instead of moving one step at a time to find empty slots ,the interval between slots is computed by adding the successive value of an arbitrary polynomial in the original hashed index.
The probe sequence will be as follows:
X = x mod Size of Hashtable
x= (x + 1 ^ 2) mod Size of Hashtable
x= (x + 2 ^2) mod Size of Hashtable
x= (x + 3 ^2) mod Size of Hashtable
….. and So on until empty slot can be found
Rehashing
It works as a similar idea to Linear and Quadratic probing, the only difference is that whenever a collision occurs a second hash function will be used to determine the next slot.
These 2 hash functions can either be the same or different and the secondary hash function is applied continuously until an empty slot is found.
The Rehashing sequence will be as follows
h(x) = { x mod Size of Hashtable } (Hashtable can be of any size).
h2(x) = { x mod Size of Hashtable + 2 } (Hashtable can be of any size).
X = x mod Size of Hashtable
If collision occurs
(h1(key) + i * h2(key)) mod Size of Hashtable
repeat by increasing i when collision occurs
In summary, hash tables are used when we want direct access to unsorted data based on a key. We would not want to use hash tables when we need to support sorting. C# uses Hashtable data structure for Hashtable class and Dictionary but they have different collision avoidance techniques. Hashtable uses rehashing while Dictionary uses Chaining.
