Consistent Hashing
Scaling horizontally requires adding more server nodes as demand increases. We use load balancing to distribute the API request among servers.
For Horizontally scaling the data we use the term sharding. If a database is partitioned into 5 shards each shard will have a subset of the total data.
Distributing data between shards requires making sure they are evenly loaded and knowing which shard owns a particular key (user). The simplest solution for this is to take the hash modulo of the number of servers.
Server = hash(Key) mod N where N is the number of servers.
Let's say we got three servers and we need to distribute load among these servers based on a user key identifier.
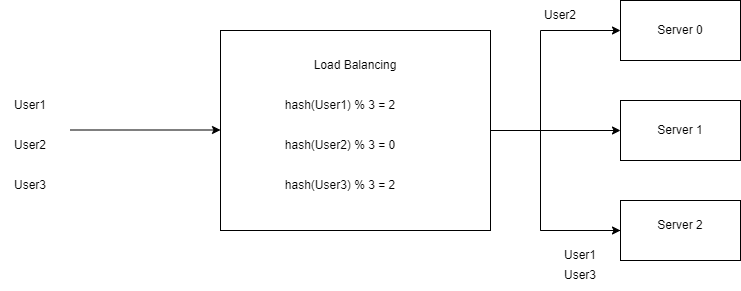
It is a stateless approach. Maps between User keys and Servers do not require any special storage. So far so good. What if due to increased load we added an additional node ? Using the same hash function, we get the same result but applying the modulo operation we get different results than before, since the number is increased by one. Now the modulo operation is based on 4 instead of 3.
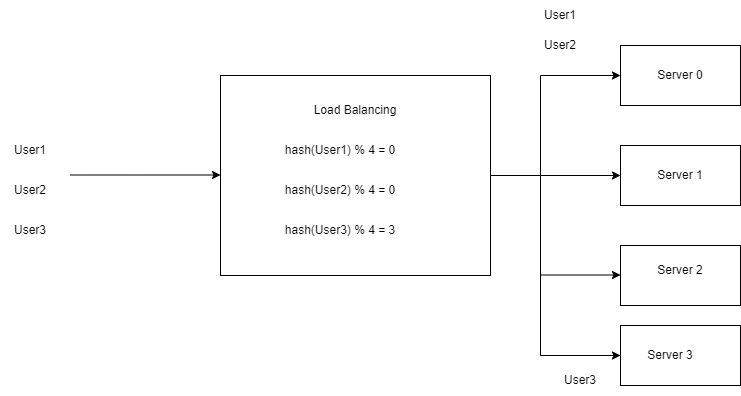
Now nearly all keys from all nodes need to be remapped. This will cause additional load in the origin.This is known as rehashing problem.
Consistent hashing
Consistent Hashing is a distributed hashing scheme that operates independently of the number of servers.
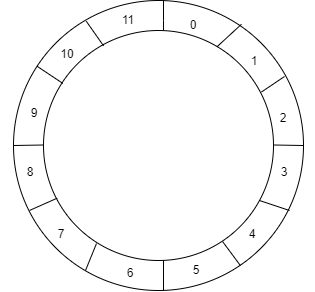
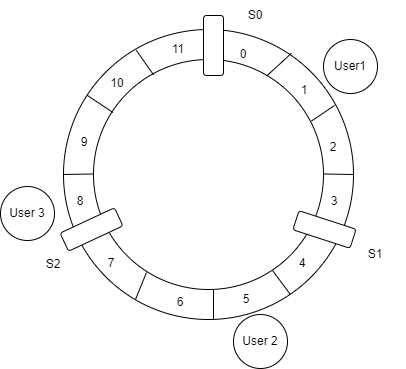
Imagine an array with 12 partitions.

We get a ring when we connect both ends.
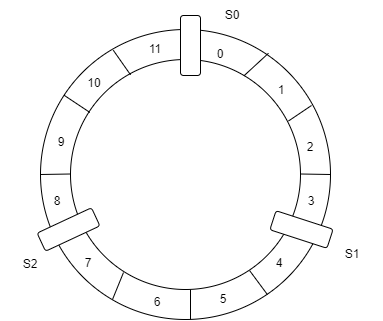
Start by placing some servers evenly distributed around the ring.
Now we need to find an index for User Keys in the ring.
Using hash modulo F = “hash(Key) mod R where R number of partitions in the ring”
Consider three users with keys User1, User2 and User3 and their hash modulos are 1, 5 and 8.
Position the users on the ring.
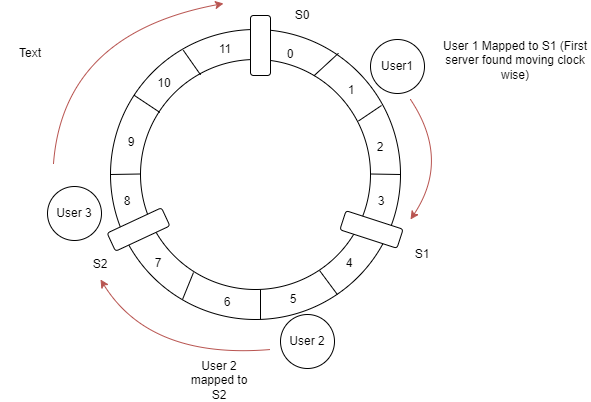
To determine which server the user maps to, simply go clockwise till we find a server.
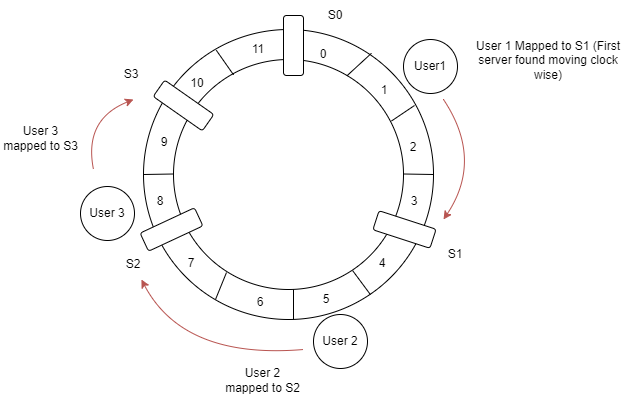
Now to add a new server , use the same hashing function we used to find users position ( F = “hash(Key) mod R where R number of partitions in the ring” ).Instead of using user key use Server identifier. So the position of the new server is decided randomly.
Ideally, each server should hold 25% of the data of each user since there are 4 servers. Let's check is this the case ?
Server S0 can hold users data of indices 10 and 11 ⇒ 16.6%
Server S1 can hold users data of indices 0,1, 2,3 ⇒ 33.3%
Server S2 can hold users data of indices 4,5,6,7 ⇒ 33.3%
Server S3 can hold users data of indices 8 and 9 ⇒ 16.6%
It's not evenly distributed. The technique called Virtual nodes or replicas is used to solve this problem.
Instead of positioning one spot per node, let's position three. We also need to define three different hashing functions. Each node is hashed three times to yield three different indexes.
Instead of server labels S1 , S2 and S3 , we will have replica servers [S10 , S11…..S19] for server S1. All user keys which are mapped in replicas Sij are stored on server Si. When a user moves clockwise and finds Sij as a replica server, the key is stored on Si.
hash0(S0) = 0 ⇒ S00
hash1(S0) = 4 ⇒ S01
hash2(S0) = 8 ⇒ S02
hash0(S1) = 2 ⇒ S10
hash1(S1) = 5 ⇒ S11
hash2(S1) = 9 ⇒ S12
hash0(S2) = 3 ⇒ S20
hash1(S2) = 6 ⇒ S21
hash2(S2) = 10 ⇒ S22
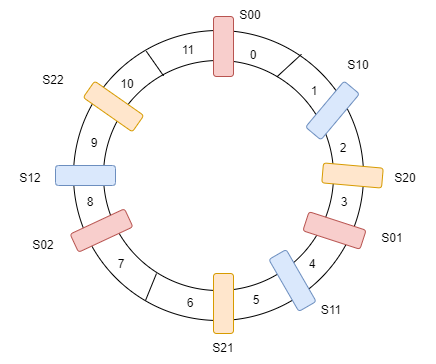
now the distribution will be
S00 ⇒ 16.67%
S01 ⇒ 8.33%
S02 ⇒ 16.67%
S10 ⇒ 16.67%
S11 ⇒ 8.33%
S12 ⇒ 8.33%
S20 ⇒ 8.33%
S21 ⇒ 8.33%
S22 ⇒ 8.33%
The more virtual nodes we define per node, the more uniform the distribution should be.
Reference and further reading:
https://dl.acm.org/doi/10.1145/258533.258660
https://ai.googleblog.com/2017/04/consistent-hashing-with-bounded-loads.html
https://arxiv.org/ftp/arxiv/papers/1406/1406.2294.pdf
http://www.eecs.umich.edu/techreports/cse/96/CSE-TR-316-96.pdf
https://itnext.io/introducing-consistent-hashing-9a289769052e
