

Bloom Filters


Bloom filters is a space efficient probabilistic data structure that answers if an element is not in a set or may be in a set. As it doesn't store the actual value, it is highly memory efficient, but on the downside, it is probabilistic. It can quickly tell if an element does not exist in the set but it cannot tell if an item is definitely present in the set.
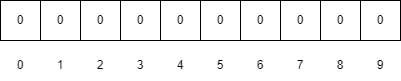
The base structure of the Bloom filter is a bit vector with all bits set to Zero. The below image shows the bloom filter of size 10
Add an element to the bloom filter
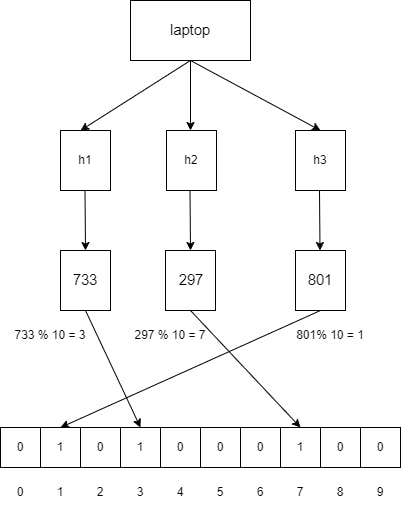
To add an element to the bloom filter , we need to pass the input through the N hash function. As an example, if we want to add the word "laptop" and we are using three hash functions, we get the following results.
h1(“laptop”) = 733
h2(“laptop”) = 297
h3(“laptop”) = 801
As the bit vector has a size of 10, we can use the mod of 10 for all these values to get the index within the bit vector.
Therefore the indexes at 733 % 10 = 3 , 297 % 10 = 7 , 801 % 10 = 1 have to be set to 1.
Check if an element exists in the Bloom filter
To check if an element already exists in the Bloom filter , pass the element through the same hash functions and modulo the result by 10.The element may be part of the set if all the bits are set as 1. If any of the bits are not set, then the element is definitely not part of the set.
Why is Bloom filter probabilistic ?
Assume that we have added two elements to the Bloom filter
“laptop” has the hash output {733 , 297 , 801} so the indexes are ⇒ { 3, 7 , 1}
“Keyboard” has the hash output { 522 , 359 , 378} so the indexes are ⇒ {2, 9 , 8}
In case we need to check if "Mouse" exists in the set , we can hash via the same hash functions. “Mouse” ⇒ {9 ,3, 1}
We have not yet added “Mouse” to the set but all the bits at index {9,3,1} are already set to 1 by the previous two elements so there is a "Mouse" in the set according to the Bloom filter. This is a false positive result.
Bloom filter applications
Bloom filters can be used as first level filtering. Some real world applications are
- The Ethereum blockchain uses Bloom filters to find logs quickly.
- Google chrome uses Bloom filters to identify malicious URLS.
- Databases use Bloom filters to reduce the disk lookups for non-existent rows or columns.
Ref :